はじめに
負荷試験って目的とは
負荷試験の指標
- スループット
- 単位時間に処理を行う量
- webシステムでは「1秒間に処理を行うHTTPリクエストの数」を示すことが多く、rps(Request Per Second)と呼ぶ
- 「ネットワーク上を流れるデータ転送速度」として利用する場合もある
- ネットワーク帯域と呼ぶ
- 単位時間に処理を行う量
- レイテンシ
システムの性能改善
- スループットの改善
- レイテンシの改善
マイクロサービスにより構築されたwebアプリケーションのテストコードではサービス間の通信が発生するケースがある。 これまではmockingjay-serverを利用して外部サービスのmockを作成しサービステストを実装していたが、エラー発生ケースのmock定義が非常に煩雑になると感じた。 且つ、マイクロサービス間で頻繁に呼ばれるAPIに関してはエラーケースを定義することで他のテストケースへの影響も発生した。 これらのことから、テストケース間で依存関係を与えない方法でサービステストが実装出来ないかを調査したところWireMockが候補に挙がったためシンプルではあるが実装例を残しておく。
本検証ではmavenを利用しているため、公式サイトの手順に沿って下記の依存性をpomに記入する。
後はmvn installで依存ライブラリをインストール出来る。
<dependency>
<groupId>com.github.tomakehurst</groupId>
<artifactId>wiremock</artifactId>
<version>2.17.0</version>
<scope>test</scope>
</dependency>
java.lang.NoClassDefFoundError: org/eclipse/jetty/util/thread/Locker
at org.eclipse.jetty.server.Server.<init>(Server.java:94)
at com.github.tomakehurst.wiremock.jetty9.JettyHttpServer.createServer(JettyHttpServer.java:118)
at com.github.tomakehurst.wiremock.jetty9.JettyHttpServer.<init>(JettyHttpServer.java:66)
at com.github.tomakehurst.wiremock.jetty9.JettyHttpServerFactory.buildHttpServer(JettyHttpServerFactory.java:31)
at com.github.tomakehurst.wiremock.WireMockServer.<init>(WireMockServer.java:74)
at com.github.tomakehurst.wiremock.junit.WireMockClassRule.<init>(WireMockClassRule.java:32)
at com.github.tomakehurst.wiremock.junit.WireMockClassRule.<init>(WireMockClassRule.java:40)
at spark.unit.service.ServiceTests.<clinit>(ServiceTests.java:26)
at sun.misc.Unsafe.ensureClassInitialized(Native Method)
at sun.reflect.UnsafeFieldAccessorFactory.newFieldAccessor(UnsafeFieldAccessorFactory.java:43)
at sun.reflect.ReflectionFactory.newFieldAccessor(ReflectionFactory.java:156)
at java.lang.reflect.Field.acquireFieldAccessor(Field.java:1088)
at java.lang.reflect.Field.getFieldAccessor(Field.java:1069)
at java.lang.reflect.Field.get(Field.java:393)
at org.junit.runners.model.FrameworkField.get(FrameworkField.java:73)
at org.junit.runners.model.TestClass.getAnnotatedFieldValues(TestClass.java:230)
at org.junit.runners.ParentRunner.classRules(ParentRunner.java:255)
at org.junit.runners.ParentRunner.withClassRules(ParentRunner.java:244)
at org.junit.runners.ParentRunner.classBlock(ParentRunner.java:194)
at org.junit.runners.ParentRunner.run(ParentRunner.java:362)
at org.junit.runner.JUnitCore.run(JUnitCore.java:137)
at com.intellij.junit4.JUnit4IdeaTestRunner.startRunnerWithArgs(JUnit4IdeaTestRunner.java:68)
at com.intellij.rt.execution.junit.IdeaTestRunner$Repeater.startRunnerWithArgs(IdeaTestRunner.java:51)
at com.intellij.rt.execution.junit.JUnitStarter.prepareStreamsAndStart(JUnitStarter.java:237)
at com.intellij.rt.execution.junit.JUnitStarter.main(JUnitStarter.java:70)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:147)
Caused by: java.lang.ClassNotFoundException: org.eclipse.jetty.util.thread.Locker
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:331)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 30 more
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-server</artifactId>
<version>9.3.14.v20161028</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-servlets</artifactId>
<version>9.3.14.v20161028</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-servlet</artifactId>
<version>9.3.14.v20161028</version>
<scope>test</scope>
</dependency>
wiremock-standaloneの依存ライブラリをpomに追加する <dependency>
<groupId>com.github.tomakehurst</groupId>
<artifactId>wiremock-standalone</artifactId>
<version>${wiremock.version}</version>
<scope>test</scope>
</dependency>
今回はマイクロサービスで構築されたアプリケーションを想定してサービステストコードを実装する。
外部サービスの呼出し結果により処理が変更される

上記処理の場合、Aサービスの「/user/insert」に対するサービステストを実装する場合、テスト結果がBサービスに依存することがわかる。
// wiremockをポートを指定して定義する @Rule public WireMockClassRule wireMockRule = new WireMockClassRule(8082); @Test public void TEST_Bサービス正常動作時() throws UnirestException { // Bサービスの正常動作をmockとする wireMockRule.stubFor(get(urlEqualTo("/mock/sample")) .willReturn( aResponse() .withStatus(200) .withHeader("Content-Type", "application/json") .withBody("OK"))); HttpResponse<String> res = Unirest.post("http://localhost:8081/user/insert") .header("Content-Type", "application/json") .asString(); assertEquals("response codeが200であること:", 200, res.getStatus()); assertEquals("response bodyがOKであること:", "OK", res.getBody()); } @Test public void TEST_Bサービス異常動作時() throws UnirestException { // Bサービスの異常動作をmockとする wireMockRule.stubFor(get(urlEqualTo("/mock/sample")) .willReturn( aResponse() .withStatus(400) .withHeader("Content-Type", "application/json") .withBody("B Service Error"))); HttpResponse<String> res = Unirest.post("http://localhost:8081/user/insert") .header("Content-Type", "application/json") .asString(); assertEquals("response codeが400であること:", 400, res.getStatus()); assertEquals("response bodyがB Service Errorであること:", "B Service Error", res.getBody()); }

当初の想定通りテストケース間で依存を与えずにサービステストの実装を行えた。かつ導入手順もシンプルである為非常に扱いやすい。 mock管理のフレームワークといえばswaggerが有名であるが、今回のようなテスト目的のみであればWireMockが導入コスト面から言ってもおすすめである。
※外部のmockサーバーに管理している場合は、mockを用いたテスト時にテストが失敗するため検知できる。 ※今回のように利用する場合は、サービス間の関連図を作成しておく必要があると思う。
マイクロサービスにより構築されたwebアプリケーションのテストコードではサービス間の通信が発生するケースがある。今回はサービス間の通信が発生するテストの実装を実装するためmockツールを検証したので導入手順を残しておく。
WireMock thoughtworksのTechnology Radarでも紹介されており、この1年間でも進化が著しいとのことなので、さっそく試してみる。
HTTPベースのAPIのシミュレータ、mockサーバー。 http://wiremock.org/ https://github.com/tomakehurst/wiremock
WireMockはjarファイルで提供されており、起動についてはこれを実行する。 http://repo1.maven.org/maven2/com/github/tomakehurst/wiremock-standalone/2.17.0/wiremock-standalone-2.17.0.jar
$java -jar wiremock-standalone-2.12.0.jar
http://localhost:8080でmockサーバーが起動する

※Chrome Postmanを使用して検証を実施
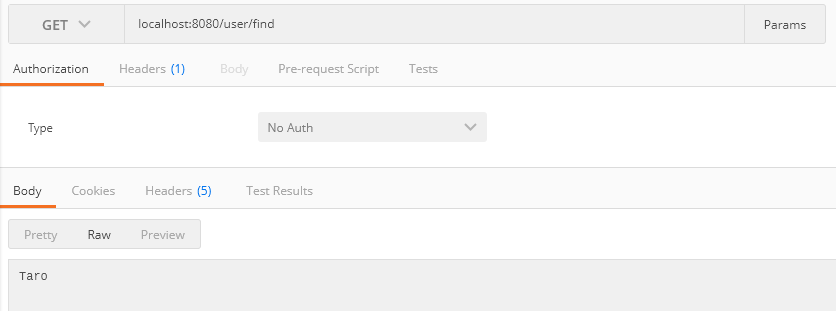
特定のリクエストに対して指定したレスポンスを返す設定を行う。
なお、マッピングにはWireMockの/__admin/mappingsAPIを使用する。
POST : /__admin/mappings
- /helloのPOST APIを定義する

登録された結果が返却される

設定した結果が返却される。

登録されたAPIはwiremock-standalone-2.12.0.jarと同一階層のmappingsに保存される。



{
"scenarioName": "findUser",
"request": {
"url": "/user/find",
"method": "GET"
},
"response": {
"status": 200,
"body": "Taro",
"headers": {
"Content-Type": "application/json"
}
}
}
__admin/docsを開きSwagger UIの管理画面で確認できる。

GitOpsというキーワードが出てきており、職場でもGitOpsを使った検証環境の運用が始まっている。
しかし、GitOps環境を構築するにあたってIaCは進めているものの、まだ人手によるOperationがなくなっていないのも事実です。
そこで、Azure上にkubernetes clusterの構築からGitOpsの仕組みを導入するまでを自動化する仕組みとして
Bedrockを検証したので手順や気づきについてまとめていきます。
Weaveworks社が提唱した,Kubernetesの運用ベストプラクティス
詳しくはGitOpsを参照
記事はボリュームがあるので 要点をまとめると下記のような感じです。
GitOpsを実現するために、 現在はFluxというOSSを使ってkubernetes clusterの状態とgit管理しているmanifestの間で 同期を取る仕組みを実現している。
fluxについて過去にチュートリアル記事を書いたので参考になればと思います。 cabi99.hatenablog.com
現在はFluxを使って下図の環境を構築しています。
この環境をpipeline以外、すべて自動で構築します。

Microsoftが提供するGitOpsワークフローを使用してKubernetesクラスターを運用可能にするterraformテンプレートです。 GitOpsワークフローは、Fabrikateの定義を中心に展開されており、構成から構成を分離する、より高い抽象化レベルで展開を指定できます。 今回の検証ではBedrockを使ってAKSクラスターを自動構築することを優先したのでFabrikateについては検証しません。
helm: v2.13.1 → 3系だとまだ動かないっぽい
terraform: v0.12.20 → テンプレートは古いバージョン対応だったのでupgradeコマンドでスクリプトを更新しました
Azure CLI
$ az version
{
"azure-cli": "2.0.80",
"azure-cli-command-modules-nspkg": "2.0.3",
"azure-cli-core": "2.0.80",
"azure-cli-nspkg": "3.0.4",
"azure-cli-telemetry": "1.0.4",
"extensions": {}
}
bedrockのテンプレートで実行している内容を簡単に書くと以下になります。
1.azure cli でresource groupを作成する
az group create -n gitOpsCluster -l japaneast

2.vnetとsubnetをterraformで作成する ※利用するfileはbedrockの以下path
/bedrock/cluster/azure/vnet
参考までにmain.tf variables.tfはresource_group_name以外、ほぼデフォルト値
resource "azurerm_virtual_network" "vnet" {
name = var.vnet_name
location = var.location
address_space = [var.address_space]
resource_group_name = var.resource_group_name
dns_servers = var.dns_servers
tags = var.tags
}
resource "azurerm_subnet" "subnet" {
count = length(var.subnet_names)
name = var.subnet_names[count.index]
virtual_network_name = azurerm_virtual_network.vnet.name
resource_group_name = azurerm_virtual_network.vnet.resource_group_name
address_prefix = var.subnet_prefixes[count.index]
service_endpoints = var.subnet_service_endpoints[count.index]
}

3.aksクラスターを作成し、fluxをinstallする ※利用するfileはbedrockの以下path
/bedrock/cluster/azure/aks-gitops
参考までにmain.tf variables.tfはfluxの設定値やkey情報以外はほぼデフォルト値
module "aks" {
source = "../../azure/aks"
resource_group_name = var.resource_group_name
cluster_name = var.cluster_name
agent_vm_count = var.agent_vm_count
agent_vm_size = var.agent_vm_size
dns_prefix = var.dns_prefix
vnet_subnet_id = "/subscriptions/${var.azure_subscription_id}/resourceGroups/${var.resource_group_name}/providers/Microsoft.Network/virtualNetworks/${var.virtual_network_name}/subnets/${var.agent_subnet_name}"
ssh_public_key = var.ssh_public_key
service_principal_id = var.service_principal_id
service_principal_secret = var.service_principal_secret
service_cidr = var.service_cidr
dns_ip = var.dns_ip
docker_cidr = var.docker_cidr
kubeconfig_filename = var.kubeconfig_filename
network_policy = var.network_policy
network_plugin = var.network_plugin
oms_agent_enabled = var.oms_agent_enabled
}
module "flux" {
source = "../../common/flux"
gitops_ssh_url = var.gitops_ssh_url #Azure DevOpsのgitで管理しているリポジトリ
gitops_ssh_key = var.gitops_ssh_key #fluxがAzure DevOpsにアクセスするためのkey
gitops_path = var.gitops_path #fluxが同期したいマニフェストのpath
gitops_poll_interval = var.gitops_poll_interval
gitops_label = var.gitops_label
gitops_url_branch = var.gitops_url_branch #fluxが同期したいbranch
enable_flux = var.enable_flux
flux_recreate = var.flux_recreate
kubeconfig_complete = module.aks.kubeconfig_done
kubeconfig_filename = var.kubeconfig_filename
flux_clone_dir = "${var.cluster_name}-flux"
acr_enabled = var.acr_enabled
gc_enabled = var.gc_enabled
}
module "kubediff" {
source = "../../common/kubediff"
kubeconfig_complete = module.aks.kubeconfig_done
gitops_ssh_url = var.gitops_ssh_url
}
Azure DevOpsでssh_keyを発行する手順はこちらを参照
Connect to your Git repos with SSH - Azure Repos | Microsoft Docs
fluxで同期を行うmanifestをkustomizeを使って管理している場合はfluxのoptionに注意する必要があります。 bedrockでfluxをインストールするのはhelmを利用しているのですが、「manifestGeneration」optionが変数として受け渡す設計がなされていないので自分たちで修正する必要があります。
/cluster/common/flux/deploy_flux.sh
#!/bin/sh while getopts :b:f:g:k:d:e:c:l:s:r:t:z: option do case "${option}" in b) GITOPS_URL_BRANCH=${OPTARG};; f) FLUX_REPO_URL=${OPTARG};; g) GITOPS_SSH_URL=${OPTARG};; k) GITOPS_SSH_KEY=${OPTARG};; d) REPO_ROOT_DIR=${OPTARG};; e) GITOPS_PATH=${OPTARG};; c) GITOPS_POLL_INTERVAL=${OPTARG};; l) GITOPS_LABEL=${OPTARG};; s) ACR_ENABLED=${OPTARG};; r) FLUX_IMAGE_REPOSITORY=${OPTARG};; t) FLUX_IMAGE_TAG=${OPTARG};; z) GC_ENABLED=${OPTARG};; *) echo "Please refer to usage guide on GitHub" >&2 exit 1 ;; esac done KUBE_SECRET_NAME="flux-ssh" RELEASE_NAME="flux" KUBE_NAMESPACE="flux" CLONE_DIR="flux" REPO_DIR="$REPO_ROOT_DIR/$CLONE_DIR" FLUX_CHART_DIR="chart/flux" FLUX_MANIFESTS="manifests" echo "flux repo root directory: $REPO_ROOT_DIR" rm -rf "$REPO_ROOT_DIR" echo "creating $REPO_ROOT_DIR directory" if ! mkdir "$REPO_ROOT_DIR"; then echo "ERROR: failed to create directory $REPO_ROOT_DIR" exit 1 fi cd "$REPO_ROOT_DIR" || exit 1 echo "cloning $FLUX_REPO_URL" if ! git clone -b "$FLUX_IMAGE_TAG" "$FLUX_REPO_URL"; then echo "ERROR: failed to clone $FLUX_REPO_URL" exit 1 fi cd "$CLONE_DIR/$FLUX_CHART_DIR" || exit 1 echo "creating $FLUX_MANIFESTS directory" if ! mkdir "$FLUX_MANIFESTS"; then echo "ERROR: failed to create directory $FLUX_MANIFESTS" exit 1 fi # call helm template with # release name: flux # git url: where flux monitors for manifests # git ssh secret: kubernetes secret object for flux to read/write access to manifests repo echo "generating flux manifests with helm template" # ここにmanifestGenerationがないため、kustomizeでmanifestをgenerateする場合はoptionを追加する必要があります。 # こんな感じ「--set manifestGeneration=true」 if ! helm template . --name "$RELEASE_NAME" --namespace "$KUBE_NAMESPACE" --values values.yaml --set image.repository="$FLUX_IMAGE_REPOSITORY" --set image.tag="$FLUX_IMAGE_TAG" --output-dir "./$FLUX_MANIFESTS" --set git.url="$GITOPS_SSH_URL" --set git.branch="$GITOPS_URL_BRANCH" --set git.secretName="$KUBE_SECRET_NAME" --set git.path="$GITOPS_PATH" --set git.pollInterval="$GITOPS_POLL_INTERVAL" --set git.label="$GITOPS_LABEL" --set registry.acr.enabled="$ACR_ENABLED" --set syncGarbageCollection.enabled="$GC_ENABLED"; then echo "ERROR: failed to helm template" exit 1 fi # back to the root dir cd ../../../../ || exit 1 echo "creating kubernetes namespace $KUBE_NAMESPACE if needed" if ! kubectl describe namespace $KUBE_NAMESPACE > /dev/null 2>&1; then if ! kubectl create namespace $KUBE_NAMESPACE; then echo "ERROR: failed to create kubernetes namespace $KUBE_NAMESPACE" exit 1 fi fi echo "creating kubernetes secret $KUBE_SECRET_NAME from key file path $GITOPS_SSH_KEY" if kubectl get secret $KUBE_SECRET_NAME -n $KUBE_NAMESPACE > /dev/null 2>&1; then # kubectl doesn't provide a native way to patch a secret using --from-file. # The update path requires loading the secret, base64 encoding it, and then # making a call to the 'kubectl patch secret' command. if [ ! -f "$GITOPS_SSH_KEY" ]; then echo "ERROR: unable to load GITOPS_SSH_KEY: $GITOPS_SSH_KEY" exit 1 fi secret=$(< "$GITOPS_SSH_KEY" base64 -w 0) if ! kubectl patch secret $KUBE_SECRET_NAME -n $KUBE_NAMESPACE -p="{\"data\":{\"identity\": \"$secret\"}}"; then echo "ERROR: failed to patch existing flux secret: $KUBE_SECRET_NAME " exit 1 fi else if ! kubectl create secret generic $KUBE_SECRET_NAME --from-file=identity="$GITOPS_SSH_KEY" -n $KUBE_NAMESPACE; then echo "ERROR: failed to create secret: $KUBE_SECRET_NAME" exit 1 fi fi echo "Applying flux deployment" if ! kubectl apply -f "$REPO_DIR/$FLUX_CHART_DIR/$FLUX_MANIFESTS/flux/templates" -n $KUBE_NAMESPACE; then echo "ERROR: failed to apply flux deployment" exit 1 fi
aksのデプロイが完了するとfluxの同期によりapplicationがデプロイされます。
今回はaksチュートリアルにあるvoteアプリを使いました。
クイック スタート:Azure Kubernetes Service クラスターをデプロイする | Microsoft Docs
デプロイされたらexternal-ipを取得してアクセス出来ます。
$ kubectl get svc -o wide NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR azure-vote-back ClusterIP 10.0.111.235 <none> 6379/TCP 10m app=azure-vote-back azure-vote-front LoadBalancer 10.0.55.117 23.102.68.224 80:31559/TCP 10m app=azure-vote-front kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 22m <none>
アクセスすると無事表示されました。

デフォルトですと「default」namespaceにfluxのpodがdeployされるので別で管理したい場合はoptionを変更したほうが良いかもしれません。
$ kubectl get po --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE default azure-vote-back-bc5b86f5f-dpskl 1/1 Running 0 14m default azure-vote-front-ccfd8667f-rt8rc 1/1 Running 0 14m flux flux-6455b87976-7thxx 1/1 Running 0 15m flux flux-memcached-5ff94b674c-t9qcm 1/1 Running 0 15m kube-system azure-cni-networkmonitor-bjxvq 1/1 Running 0 22m kube-system azure-ip-masq-agent-pltrz 1/1 Running 0 22m kube-system azure-npm-79bxx 2/2 Running 0 17m kube-system coredns-544d979687-dzrxw 1/1 Running 0 26m kube-system coredns-autoscaler-546d886ffc-s8ssf 1/1 Running 0 26m kube-system dashboard-metrics-scraper-867cf6588-9llkt 1/1 Running 0 26m kube-system kube-proxy-nvxvm 1/1 Running 0 22m kube-system kubernetes-dashboard-7f7676f7b5-dnrcc 1/1 Running 0 26m kube-system metrics-server-75b8b88d6b-spllf 1/1 Running 1 26m kube-system tunnelfront-6dcfb8d9d9-vrtvr 1/1 Running 0 26m
検証していて気になったこととして、FluxのDocker imageのリポジトリです。 もともとfluxはFlux projectの「fluxcd」リポジトリからpullしていると想定していましたが 実際はweaveworksのリポジトリからでした。
両リポジトリを比較するとfluxcdの方がversionは新しいようです。
weaveworks weaveworks/flux:1.14.2 fluxcd fluxcd/flux:1.17.1
この違いに関しては
weaveworksの「Flagger」というプロダクトがFluxを利用したcanary デプロイを実現する仕組みがあり対応しているFluxをweaveworks自身が管理しているのではないかと推測しています。
今回はbedrockを使ってAzure上にGitOps対応のAKSクラスターを手動で作成しました。
これらの工程はAzure DevOpsのpipelinesのようなCIツールで自動化することが可能なので自動化できればエンジニアは 特に意識せずにテスト環境を構築できるようになります。
fluxを使ってclusterのgitOpsは実現できていますが、terraformのコードと環境が同期を取っているわけではないので、 実際に環境に関してもgitOpsを行いたい場合はFabrikateを導入してCI pipelineを構築することが必要になります。
検証してみた感想としてあまり抽象化しすぎると、管理や保守の面で結果的に属人化してしまう恐れもあるので テスト環境のような使い捨ての環境を作る場合は、今回のようなterraformスクリプトを自動化するpipelineのみでも十分だと感じました。
みなさんの現場はデリバリーチームとオンコールチームに分かれていますでしょうか?
分かれている現場ではリリースのタイミングは調整が出来ていますか?
我々のチームはデリバリーチームとオンコールチームに分かれているのですが、テスト環境などの関係上 リリースのタイミングの調整に時間がかかりがちで、そのたびにmaster branchのコンフリクトに悩まされてしまったり merge待ちなどが発生してデリバリーのリードタイムが伸びてしまうことがあります。
そこで今回は本番コードに潜在的にプロダクトのコードを埋め込んでも 影響が出ない仕組みが実現できる「Feature Toggles」について調べてみたので整理してみようと思います。 ※この記事ではFeature Togglesの具体的な実装については記載しません
Feature Togglesは別名:Feature Flagとも呼ばれており、チームがコードを変更することなくシステムの振る舞いを変更することができる仕組みであり、さまざまな用途が存在しているようです。 ちなみに私が初めてFeature Togglesを知ったのは Martin Fowlerのblog記事でした。 今回の記事もこちらで記載されている情報やFeature Togglesを実現するProductの内容を自分なりに噛み砕いて整理しています。 martinfowler.com
Togglesを実装したり、管理したりする場合、数が増えていくと複雑になる傾向があるので カテゴリ分けを考えることは重要であり、複雑性をコントロールをする事が推奨されています。
調べてみるとFeature Togglesにはいくつかカテゴリがあり、自分達の課題にある内容も Feature Togglesのカテゴリの中に存在していました。
継続的デリバリーを実践するチームのためにトランクベースの開発を可能にするために使用される機能フラグです。Release Togglesを使用すると 進行中の機能をmaster branchなどにmerge出来るようにし、いつでも本番環境に展開出来るようになります。
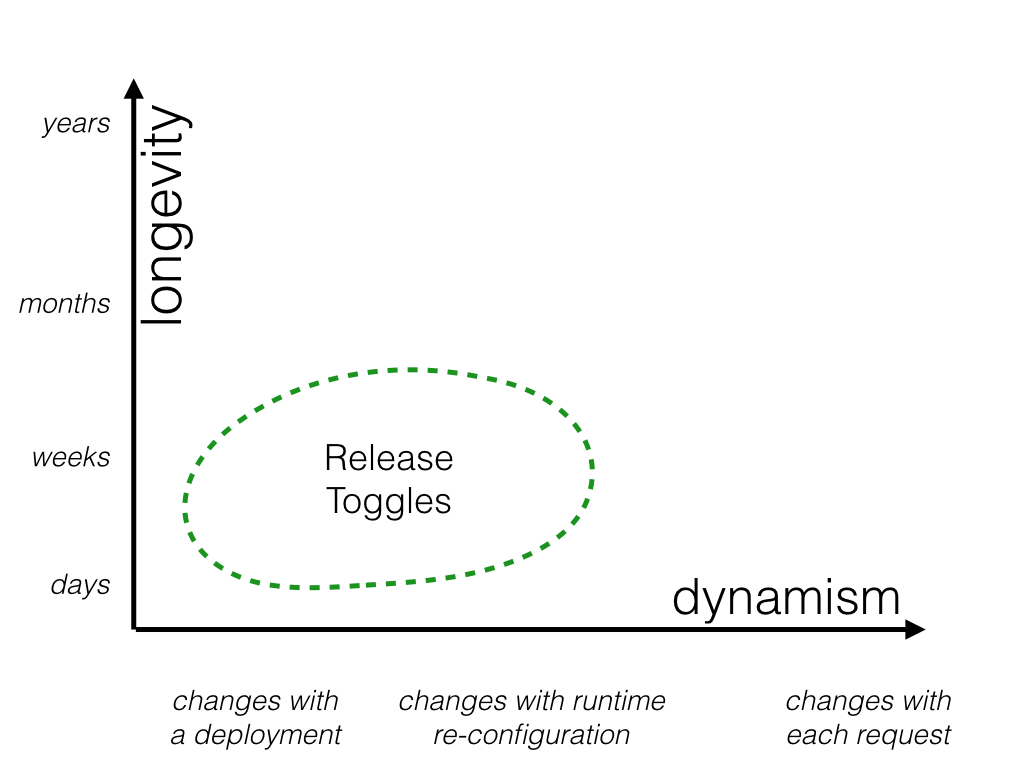
Release Togglesは、一般的に1週間から2週間以上にわたっては存在しないことが推奨されています。 ただし、プロダクト中心のトグルについては長期間埋め込まれていることもあります。 Release Togglesを用いたトグル戦略は非常に静的で、トグルコンフィグレーションの変更して新しいリリースをトグルで展開することの決定は、大抵受入れ易いものになります。
A/Bテストやカナリアテストを実現するために使用されます。 仮説検証のプロダクトや非機能要件の実装を一部のユーザーにのみ公開して動作を追跡することで、効果を比較できます。 この手法は、通常、データ駆動型の最適化に使用されます。 また、この手法を採用する場合はシステム監視の仕組みやユーザーインタビューのようなデータを収集する術をあらかじめ用意していることが望ましいです。
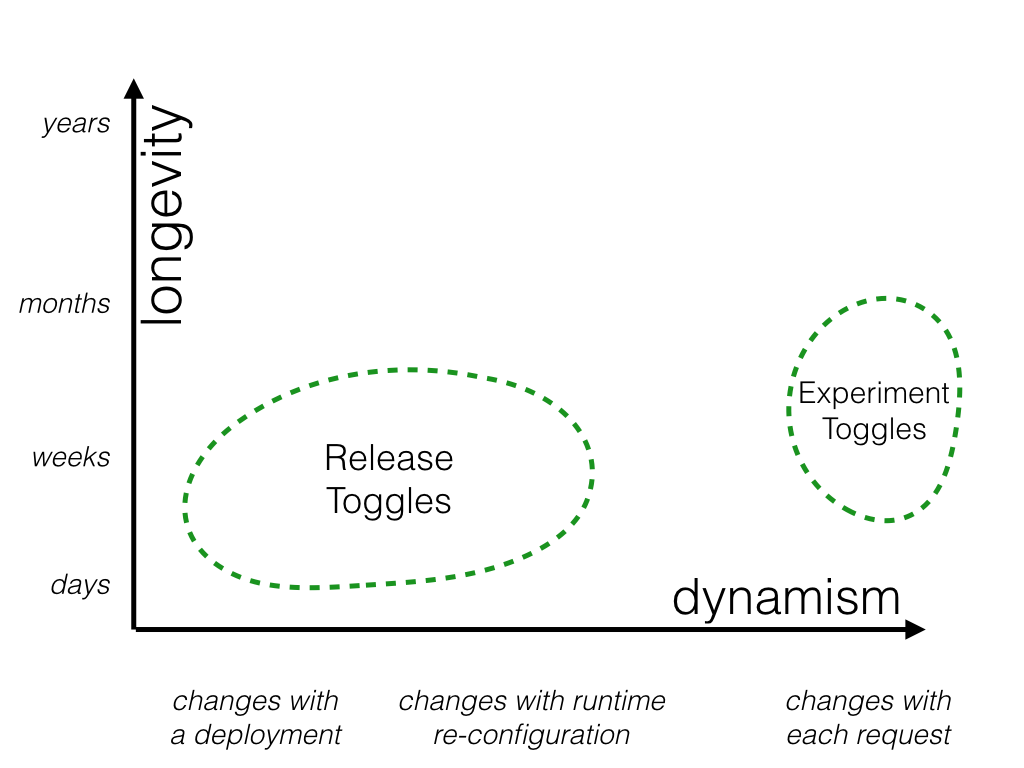
Experiment Togglesは、統計的に有意なデータを収集するために十分な期間の同じ構成を維持する必要があります。 実験の内容にもよって、一般的に時間や週単位が推奨されています。また、システムに変更を加えてしまうと実験の結果が無効になるリスクが存在するので、これ以上長く期間を設定することは有用ではありません。
システムの動作の運用面を制御するために使用されます。 パフォーマンスへの影響が不明確な新機能をロールアウトする際にOps Togglesを導入して、Opsチームが必要に応じて本番環境でその機能を迅速に無効化または低下できるようにします。 この仕組みを導入することによってシステム障害時のMTTRが向上すると考えられます。 ※MTTRは障害から回復するまでの平均時間なので、トグルをoffにしたときに「回復した」と定義して良いか、少し迷っています…
Ops Togglesは短い期間でしか存在しておらず、新機能の運用面で安定したらフラグを廃止します。 個人的にはOps作業のボリュームからOps Togglesの上限を設けて、カンバン開発のWIP制御と連動するとDevOpsが良い感じになりそうな予感がします。
ちなみに、Ops Togglesのテクニックとして システムが異常に高い負荷に耐えている場合、Opsチームが重要でないシステム機能を正常値に低下させることができる例外的に長寿命の「Kill Switches」という概念が存在しているようです。 例えば、システムに高負荷がかかっている場合は、機能的には重要ではないが表示コストがかかる項目を一時的にoffするといったイメージです。 これらのOps Togglesを長寿命で管理して手動切り替えられるで管理される「Circuit Breaker」として利用することもあります。
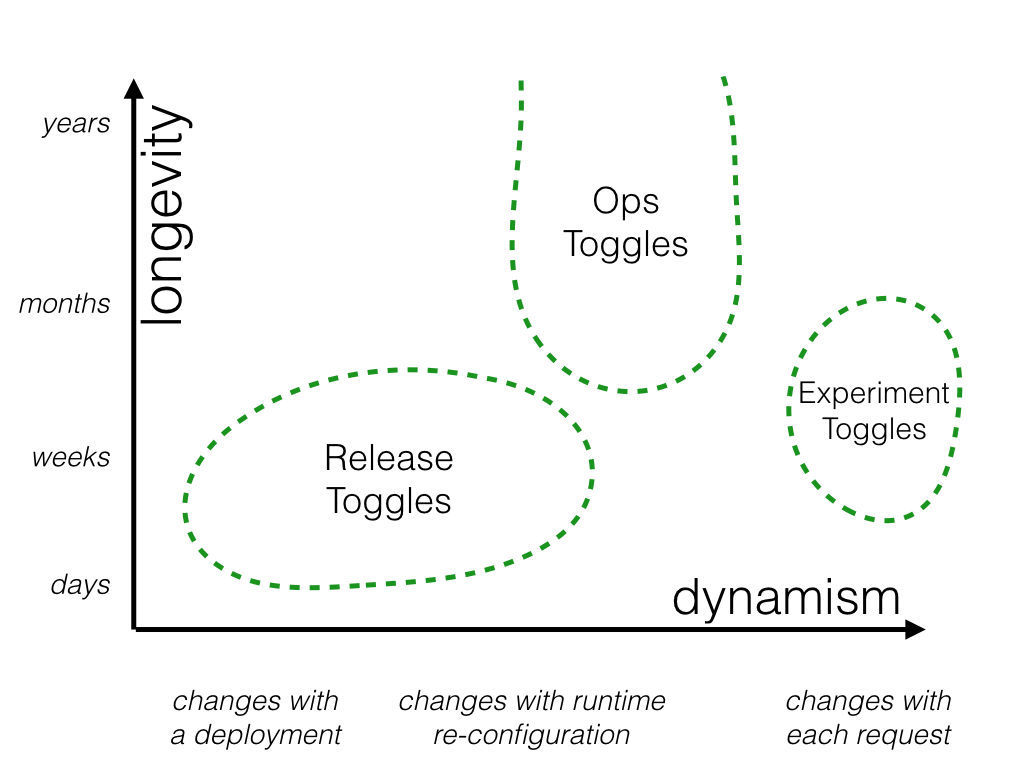
特定のユーザのみ機能を変えたり、プロダクトのエクスペリエンスを変えたりするのに使われます。 個人的には、Experiment Togglesとの違いはプロダクトとして完成しているかしていないかだと捉えました。 Experiment Togglesはプロダクトが正しいものなのかを実験するためのもの、Permissioning Togglesは正しいものと判断できた機能を 特定のユーザーに提供する仕組みだと思います。
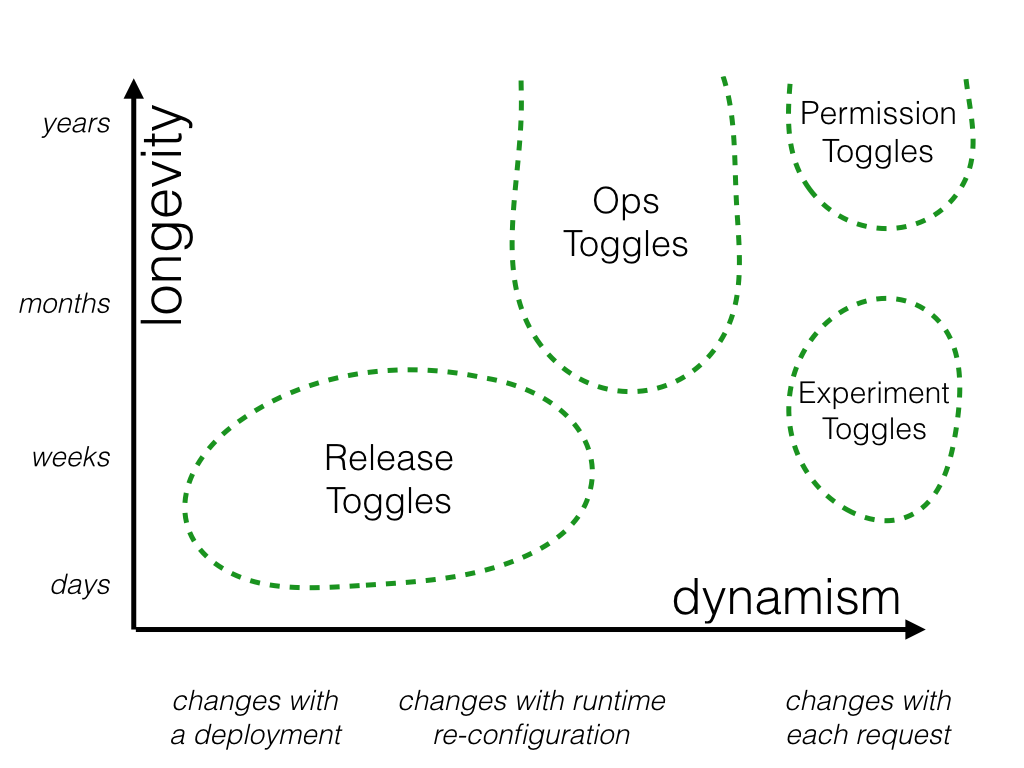
公開する機能を管理する方法として使う場合には、Permissioning Togglesは、ほかのカテゴリの機能トグルに比べてとても長期間生存するものになります。 切り替えは、いつもリクエスト毎になるので、このトグルは非常に動的なものである必要があります。
トグルのカテゴリについて紹介しましたので、ここでは各トグルの管理方法について整理します。 トグルはカテゴリ毎に、静的/動的および長期間/短期間の2軸で考えることが出来ます。
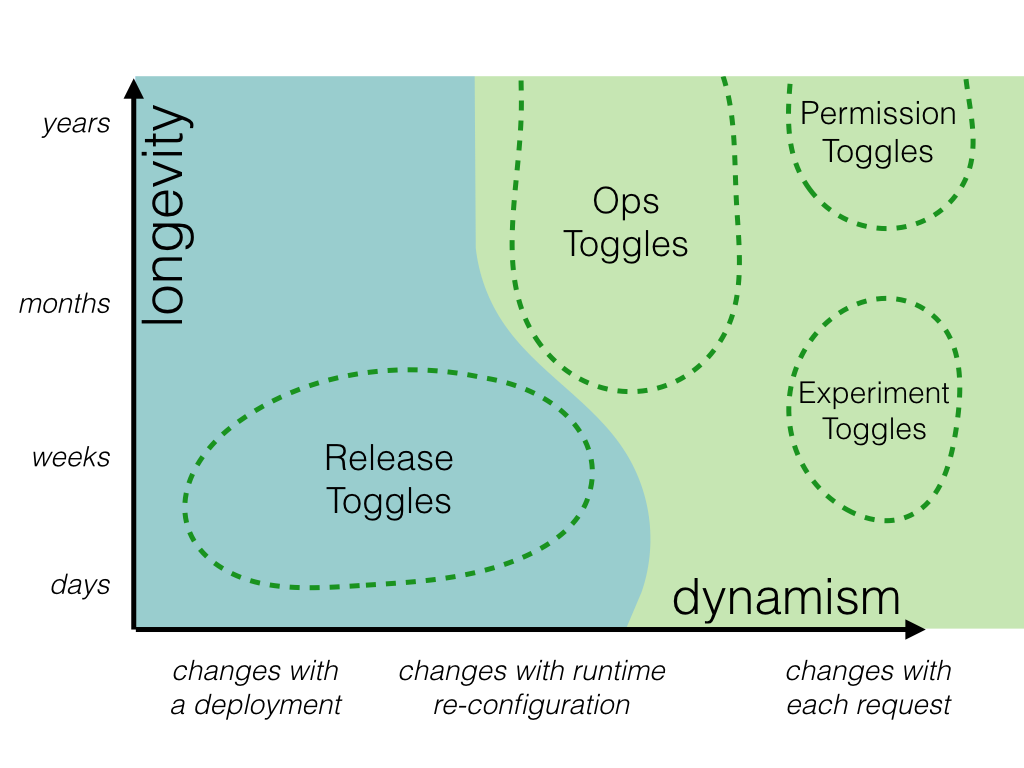
Martin Fowlerのblog記事では静的トグルは「Release Toggles」のみとなっています。 Release Togglesの用途は、本番環境に実装途中の機能を統合するための仕組みなので動的に切り替えられる必要がなく 設定ファイル等にon/offを設定すれば良さそうです。
動的トグルは、トグルの切り替えのためにリリースするのは非常にコストがかかる作業になるので 別の仕組みを提供する必要があります。 例を挙げると下記のような方法が考えられます。
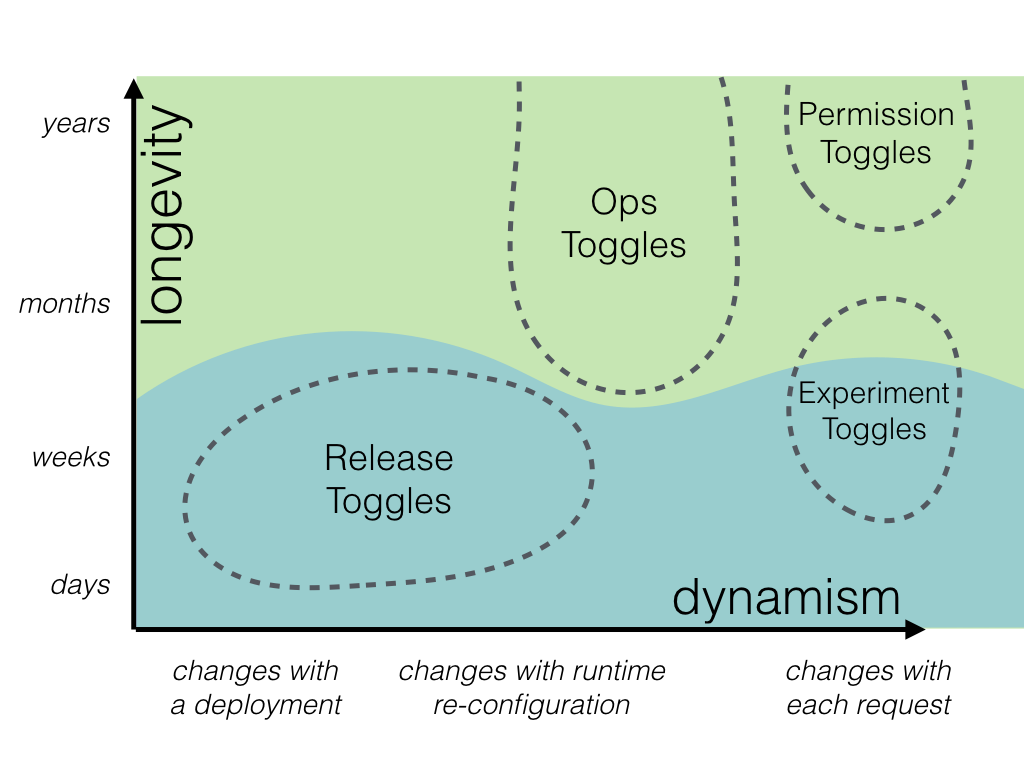
短期間トグルは、トグル判定を行うコード上にif/elseのようにハードコーディングしても良いと思います。 短期間のため、リリースサイクルの過程でif/elseの記述がなくなると予想されるからです。
function reticulateSplines(){ if( featureIsEnabled("use-new-SR-algorithm") ){ return enhancedSplineReticulation(); }else{ return oldFashionedSplineReticulation(); } }
一方で長期間トグルの場合はif/elseのコードがいつまでも残っているのは保守の観点からも リスクが発生します。blog記事でも保守可能な実装技術を採用する必要があるの述べられています。
ここから先の記述ではFeature Toggles の切り替え分岐部分をトグルポイント、切り替え判定の値取得部分をトグルルーターと表現します。 トグルポイントはFeature Togglesの数とともにはコードベース全体に増殖する傾向があります。 トグルポイントの実装が増殖した場合は、保守が非常に煩雑になり本番障害へのリスクも増加します。 ここではトグルポイントを実装する際の実装パターンを紹介していきます。
Feature Togglesを実装する際の注意点はトグルポイントの処理と決定ロジックの統合をしないことです。 例として下記のコードを紹介を紹介します。
const features = fetchFeatureTogglesFromSomewhere(); function generateInvoiceEmail(){ const baseEmail = buildEmailForInvoice(this.invoice); if( features.isEnabled("next-gen-ecomm") ){ return addOrderCancellationContentToEmail(baseEmail); }else{ return baseEmail; } }
if/else時の判定にnext-gen-ecommの値を取得して切り替えているので 一見、シンプルで可読性の高い実装のように見えますが非常に保守が大変になります。 まず、トグルルーターを呼び出すのが、他のメソッドでも必要にあった場合に すべてのメソッドに同様の処理を施す必要があります。 結果的に非常に冗長したコードになり開発時のコストを増加させる危険があります。
そこでトグルルーターを別オブジェクトとして実装します。
function createFeatureDecisions(features){ return { includeOrderCancellationInEmail(){ return features.isEnabled("next-gen-ecomm"); } // ... additional decision functions also live here ... }; }
FeatureDecisionsオブジェクトを導入しているので、機能切り替えの決定ロジックの収集ポイントとして機能します。 これによってトグルルーターの保守が簡潔になります。
そして先ほどのトグルポイントの実装は下記のようになります。
const features = fetchFeatureTogglesFromSomewhere(); const featureDecisions = createFeatureDecisions(features); function generateInvoiceEmail(){ const baseEmail = buildEmailForInvoice(this.invoice); if( featureDecisions.includeOrderCancellationInEmail() ){ return addOrderCancellationContentToEmail(baseEmail); }else{ return baseEmail; } }
切り替えの決定が抽象化されているので開発者はその中身をあまり気にせずに実装を続けることが可能になります。
上記で紹介したトグルポイントをif/elseで実装するケースは、短期間トグルには有効なテクニックですが 長期間トグルではアンチパターンとされています。 より保守可能な代替手段は、ある種の戦略パターンを使用してコードを実装することが推奨されています。
function identityFn(x){ return x; } function createFeatureAwareFactoryBasedOn(featureDecisions){ return { invoiceEmailler(){ if( featureDecisions.includeOrderCancellationInEmail() ){ return createInvoiceEmailler(addOrderCancellationContentToEmail); }else{ return createInvoiceEmailler(identityFn); } }, // ... other factory methods ... }; }
上記の例ではfactoryパターンを採用した場合の実装になります。 この実装では「featureAwareFactory」というオブジェクトを実装しており その中で、メールの送信に必要なオブジェクトをトグルポイントで作り分けています。
このように実装することによってトグルポイントがコードベースに散りばめられることや コードの修正漏れに対するリスクの軽減になります。
Feature Togglesの記事について読み込んで整理してみました。 結果としてもともとのissueであったチーム間のコンフリクトやリリースのリードタイムはFeature Togglesを導入することで解決できそうなことが分かりました。 特に私たちのチームでは「Release Toggles」と「Ops Toggles」が有効に機能しそうです。 リリース戦略を考えるうえで強力な手法なのでこれを気にしっかり導入してみようと思います。 また、将来的にはOutcome Deliveryのために「Experiment Toggles」を導入してより「正しいもの」を見つけるための仕組みとして強力な手法になりそうな予感です。
一方、課題として見えたことは 各カテゴリのトグルを単一管理するとOps作業が大変になり運用障害が起こりうること、運用していくうえでダッシュボードのように トグルの状態を可視化できる仕組みが求められる可能性が高いこと、Feature Togglesが単一障害点にならないように設計する必要があることなどなど やることはたくさんありそうな気がしました。
ダッシュボードや堅牢性を担保する場合は、自分たちで実装するのもありですが下記の製品を検証してみようと思います。 launchdarkly.com
簡単に説明するとFeature Togglesを管理してくれる製品です。 java, javascript, node, pytho..etcなどの対応言語が多いこととdatadogなどの監視システムとの親和性も高そうなので期待しています。
今回の記事は基本的に下記のblogを参考にしました。 個人的には非常によくまとめられているので導入が進んでいくにつれて読み直すと気づきも多くなりそうです。 https://martinfowler.com/articles/feature-toggles.html
皆さんのチームでは、チームの成長のためにどのような取り組みを実施していますか?
私たちのチームでは、メンバーに学習文化をつけて個々のスキル向上を図り、結果的にチームの成長につながると考えていました。 チームはスクラム開発を実施しており、スプリント内のキャパシティに毎日20%の学習時間を計画して メンバーがスキル向上やチームビルディングに充てる時間を確保しています。
時間を確保していると言えば聞こえは良いかもしれませんが、もともと業務時間内での 学習時間確保の文化が存在していたわけではないので、実際はタスクに追われて学習時間を確保できていなかったり チームで必要なスキルではない分野の学習を進めていたり、学習時間を有効に活用できていませんでした。
※チームで必要なスキルではない分野の学習をしてはいけないわけではなく、チームで開発していくにあたって最低限必要なスキルは皆で統一したいという意味です。
これまでチームの成長のために取り組んできたプラクティスを紹介します。
設計・開発・テスト・ドキュメントまでプロダクトをデリバリーする一連の流れをメンバーがペア作業で実施しました。 ペア作業で行うことで暗黙知の共有が出来たり、テスト品質が上がるなど効果が表われました。
設計・開発・テスト・ドキュメントまでプロダクトをデリバリーする一連の流れをメンバーがモブ作業で実施しました。 ステークホルダーとなるメンバーを招待して、実施することでペアプログラミングを実施していた時の効果に加えて スプリント計画時の手戻りが減るなど、こちらも効果は大きかったです。
どちらのプラクティスも効果が大きく、チームではタスクの粒度によって使い分けを行っており プラクティス自体は今後も続けていくことになりました。
スプリントの振り返りでFun/Done/Learnを実施したときに、「Learn」の枠に付箋が少なくなってきた ペア/モブでは、基本的にタスクをこなすことを優先しているので、フレームワークややり方に慣れてくると形骸化しがちという意見もちらほらありました。
「Learning Session」を導入してチームで学習時間を確保する
チームで良い感じに学習することを探していたらこちらの記事が見つかりました。
紹介した記事に記載はありますが、極力負担がかからないこと
成果物にこだわらないこと
楽しくやること
お互いに敬意をもって参加すること
メンバーがoutputする習慣がついた
キャパシティが上がった
チーム学習という仕組みを導入して1ヶ月たったが、チームの雰囲気が良くなったり 以前より楽しく仕事ができていることが実感できる。 エンジニアの定常業務の中に「学習」があるのは、とても重要で結果的に仕事が早く終わることにつながるという 成功体験をチームで出来たのは非常に良かった!
学習文化をチームに定着させたい方がいたら是非「Learning Session」を試してみてください!
Weaveworks社が提唱した,Kubernetesの運用ベストプラクティス
詳しくはGitOpsを参照
Kubernetesへのコンテナの展開を自動化するツール
Githubを見ると以下のことが書かれていた
gitでシステムの望ましい状態を宣言的に記述できる
宣言出来るものは自動化できる
コンテナをpushするのではなくコードをpushするのだ
詳細はここでは割愛するが 実現できることを簡潔に表現すると kubernetes Clusterの状態とGit管理されているmanifestと同期を取り 変更検知された場合に自動的にclusterを更新してくれるものらしい
brew install fluxctl
https://docs.fluxcd.io/en/stable/tutorials/get-started.html
基本は手順通りなのだが自分は英語を読むのに時間がかかるので実行したコマンドをメモしておきます
clusterにflux用のnamespaceを作成する
kubectl create ns flux
fluxをinstallする GHUSERはgithubのアカウント名に変更する 今回はgithubを利用しているが他のversion管理ツールを利用している場合は検証が必要そう
export GHUSER="hogehoe"
fluxctl install \
--git-user=${GHUSER} \
--git-email=${GHUSER}@users.noreply.github.com \
--git-url=git@github.com:${GHUSER}/flux-get-started \
--git-paths=namespaces,workloads \
--namespace=flux | kubectl apply -f -
コマンドを実行するとfluxがデプロイされているか確認します。
kubectl get all -n flux NAME READY STATUS RESTARTS AGE pod/flux-69f4b44484-t6lrt 1/1 Running 0 178m pod/memcached-7c45dbdb45-s4m95 1/1 Running 0 178m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/memcached ClusterIP 10.97.207.98 <none> 11211/TCP 178m NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/flux 1/1 1 1 178m deployment.apps/memcached 1/1 1 1 178m NAME DESIRED CURRENT READY AGE replicaset.apps/flux-69f4b44484 1 1 1 178m replicaset.apps/memcached-7c45dbdb45 1 1 1 178m
Fluxの公開鍵をリポジトリに登録します Clusterの状態をgitと同期するには,公開鍵を使ってGitHubリポジトリに書き込みアクセス権を持つデプロイキーを作成する必要があるようです。 デプロイキーの作成はこちらを参照
fluxctl identity --k8s-fwd-ns flux
ちなみにこの時点で Flux同期用のリポジトリに管理されているmanifestがcluster上にデプロイされていました。 guthubのmanifest抜粋
--- apiVersion: apps/v1 kind: Deployment metadata: name: podinfo namespace: demo labels: app: podinfo annotations: flux.weave.works/automated: "true" flux.weave.works/tag.init: regex:^3.10.* flux.weave.works/tag.podinfod: semver:~2.1 spec: strategy: rollingUpdate: maxUnavailable: 0 type: RollingUpdate selector: matchLabels: app: podinfo template: metadata: annotations: prometheus.io/scrape: "true" labels: app: podinfo spec: initContainers: - name: init image: alpine:3.10 command: - sleep - "1" containers: - name: podinfod image: stefanprodan/podinfo:2.1.3 imagePullPolicy: IfNotPresent ports: - containerPort: 9898 name: http protocol: TCP command: - ./podinfo - --port=9898 - --level=info - --random-delay=false - --random-error=false env: - name: PODINFO_UI_MESSAGE value: "Greetings change pod!" livenessProbe: httpGet: path: /healthz port: 9898 readinessProbe: httpGet: path: /readyz port: 9898 resources: limits: cpu: 1000m memory: 128Mi requests: cpu: 10m memory: 64Mi
kubectl get pod -n demo NAME READY STATUS RESTARTS AGE podinfo-5645bc6c54-lmcnk 1/1 Running 0 146m podinfo-5645bc6c54-tln7j 1/1 Running 0 146m
sampleのServiceはclusterIPなのでportforwadしてブラウザでアクセスしてみます
kubectl port-forward svc/podinfo 8080:9898 -n demo Forwarding from 127.0.0.1:8080 -> 9898 Forwarding from [::1]:8080 -> 9898
manifestのenvで定義されている「PODINFO_UI_MESSAGE」の値が表示されているっぽい

ここからはmanifestの内容を変更してgithubにpushしてみます PODINFO_UI_MESSAGEの内容を「Hello!!」に変更後,push
env: - name: PODINFO_UI_MESSAGE value: "Hello!!" livenessProbe: httpGet: path: /healthz port: 9898 readinessProbe:
Defaultでは5分単位で同期を取るようですがすぐに確認したかったためコマンドを実行します
fluxctl sync --k8s-fwd-ns flux
同期を取った時に監視していると差分検知されて自動的デプロイされたことがわかりました
kubectl get po -n demo -w NAME READY STATUS RESTARTS AGE podinfo-f55d5f6d9-v4phs 0/1 Pending 0 0s podinfo-f55d5f6d9-v4phs 0/1 Pending 0 0s podinfo-f55d5f6d9-v4phs 0/1 Init:0/1 0 0s podinfo-f55d5f6d9-v4phs 0/1 Init:0/1 0 2s podinfo-f55d5f6d9-v4phs 0/1 PodInitializing 0 3s podinfo-f55d5f6d9-v4phs 0/1 Running 0 4s
再度アクセスしてみると表示が「Hello!!」に変わっています

ひとまず動作させることを目的としていたので思っていたより簡単に導入出来て良かったです。 GitOpsはkubernetesを運用していくにあたって非常に強力なプラクティスになると思うので引き続きfluxを掘り下げていこうと思います。
今回は全体的に公式ページを参考にさせて頂きました。 チュートリアルはシンプルでイメージを掴むのに最適だと思います。
https://docs.fluxcd.io/en/stable/index.html
現在はKustomizeを使ってmanifestを管理しているのでゆくゆくはこちらも試してみたいです。
https://docs.fluxcd.io/en/stable/tutorials/get-started-kustomize.html
local環境でのcluster構築はminikubeでも良かったのですがdocker desktopが既にinstallされていたのでそちらを使っています