背景
Microsoftの AKS を利用して kubernetes を運用しており、podのauto scaleはHorizontal Pod Autoscalerの機能を利用しています。 Horizontal Pod Autoscalerは、簡単に説明すると指定したmetricをpodから取得して、閾値に達した場合、podをauto scaleする仕組みです。 これはkubernetesでcontainerを安定し運用するための便利な仕組みです。しかし、kubernetesのリソースに対して監視するため 外部リソースの状態に応じてpodをscaleする場合は、別の仕組みを検討する必要があります。
KEDAとは
KEDA (Kubernetes Event-driven Autoscaling)は、 kubernetes clusterに追加できる単一目的の軽量コンポーネントで、CNCFのSandboxプロジェクトにホストされているkubernetesベースのイベント駆動オートスケーラーです。宣言的に定義されたイベントに応じて、kubernetesの任意のコンテナーのスケーリングを促進できる。Horizontal Pod Autoscalerなどのkubernetesコンポーネントと連携して動作し、上書きや重複なしに機能拡張できます。
KEDAの役割
KEDAはkubernetes内で2つの重要な役割を果たします。
Agent kubernetes deploymentをアクティブ/非アクティブ化を管理します。
Metrics kubernetes metricsサーバーとして機能します。キューの長さやストリームラグなどのイベントデータをHorizontal Pod Autoscalerに公開してscale outを促進します。ソースから直接イベントを消費するのはDeploymentの役割であり、これにより、豊富なイベントの統合が維持され、キューメッセージの完了や破棄などのジェスチャーをそのまま使用できます。
Architecture
公式の説明からKEDAはetcdや外部リソースを監視して標準のHPAや対象podに命令します。
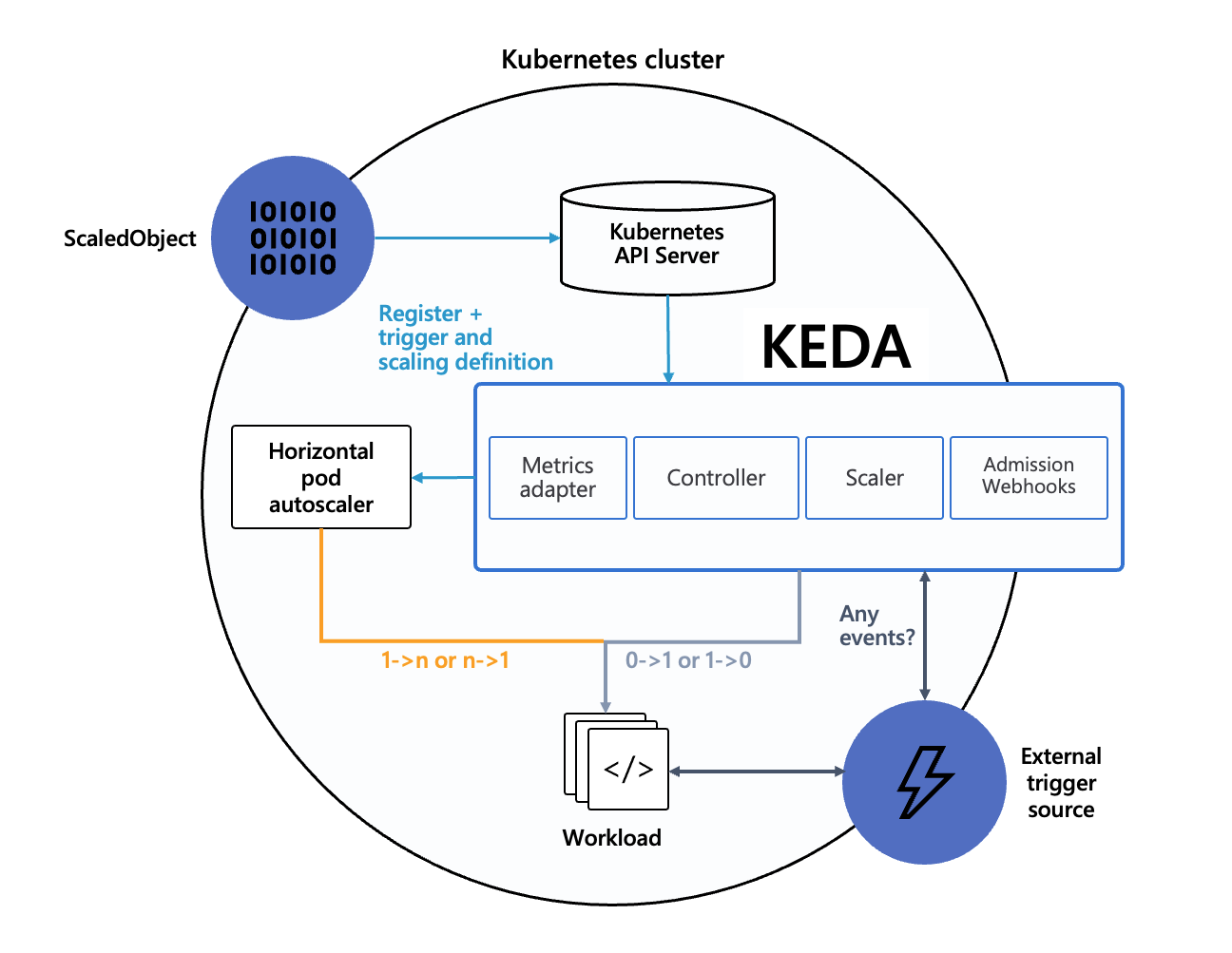
対象ソース
AWSやAzureなど幅広く対応しています。また、「External」リソースを利用することで柔軟なevent操作ができます。 詳細はこちら https://keda.sh/docs/concepts/#event-sources-and-scalers
デプロイ
今回はYAML Manifestを使ってdeployします。 ※HelmやOperatorも可
- KEDAのrepositoryをcloneし、CRDを作成する
kubectl apply -f ./deploy/crds
- scaleとtriggerを行うCRDがあることを確認する
$ kubectl get crds NAME CREATED AT scaledobjects.keda.k8s.io 2020-04-21T01:43:13Z triggerauthentications.keda.k8s.io 2020-04-21T01:43:13Z
- CRDを作成したらKEDA operatorとmetrics serverを作成する
kubectl apply -f ./deploy
- デフォルトでは「keda」namespaceに作成される
$ kubectl get all -n keda NAME READY STATUS RESTARTS AGE pod/keda-metrics-apiserver-f465ccb68-wdk5l 1/1 Running 0 23h pod/keda-operator-8fdf64d5-pkwf9 1/1 Running 0 23h NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/keda-metrics-apiserver ClusterIP 10.105.111.250 <none> 443/TCP,80/TCP 23h service/keda-operator-metrics ClusterIP 10.110.125.60 <none> 8383/TCP,8686/TCP 23h NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/keda-metrics-apiserver 1/1 1 1 23h deployment.apps/keda-operator 1/1 1 1 23h NAME DESIRED CURRENT READY AGE replicaset.apps/keda-metrics-apiserver-f465ccb68 1 1 1 23h replicaset.apps/keda-operator-8fdf64d5 1 1 1 23h
これでKEDAのdeployは完了です。
動作確認
KEDAのdeployが完了したので実際外部リソースをtriggerしてpodのauto scaleを確認します。 今回はnginxのpodをAzure storage accountのblob container file uploadイベントをhookしてpodをscaleさせます。
簡単なサンプルですがこちらに載せておきます。 https://github.com/JunichiMitsunaga/keda-example
- Azureにresource groupとstorage accountを作成する
az group create --location japaneast --name keda-example az storage account create --name kedaexample --resource-group keda-example
- connection stringを取得する
az storage account show-connection-string --name kedaexample
- 取得したconnection stringでk8sのsecretを作成する
01-secret.yaml
apiVersion: v1 kind: Secret metadata: name: account-secret namespace: keda-scale data: connectionString: ***
- auto scale用のpodをdeployする
kubectl apply -f .deploy/
- 「keda-scale」namespaceにpodがdeployされていることを確認する
$ kubectl get all -n keda-scale NAME READY STATUS RESTARTS AGE pod/scale-nginx-898f5b6d4-x8897 1/1 Running 0 46s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/scale-nginx 1/1 1 1 47s NAME DESIRED CURRENT READY AGE replicaset.apps/scale-nginx-898f5b6d4 1 1 1 46s
- KEDAによるscaleを実施するために「ScaledObject」をデプロイする
kubectl apply -f keda-hpa/
- 「ScaledObject」がdeployされていることを確認する
$ kubectl get ScaledObject -n keda-scale NAME DEPLOYMENT TRIGGERS AGE azure-blob-scaledobject scale-nginx azure-blob 28s
ScaledObjectをdeployするとscale条件にマッチしてないため該当のpodは0スケールされます。 ※この仕組みは地味にうれしいですね
$ kubectl get po -n keda-scale No resources found in keda-scale namespace.
- triggerを満たしてauto scaleを確認する 今回のtriggerはblob containerにfileを2つ以上uploadすること
1つ目のfileをuploadする 条件を満たしていないのでscaleされない
$ kubectl get po -w -n keda-scale
2つ目のfileをuploadする 条件を満たすのでpodがscale outされる
$ kubectl get po -w -n keda-scale NAME READY STATUS RESTARTS AGE scale-nginx-898f5b6d4-zhgdm 0/1 Pending 0 0s scale-nginx-898f5b6d4-zhgdm 0/1 Pending 0 0s scale-nginx-898f5b6d4-zhgdm 0/1 ContainerCreating 0 0s scale-nginx-898f5b6d4-zhgdm 1/1 Running 0 4s
fileを削除して条件を満たさないように変更する
$ kubectl get po -n keda-scale -w NAME READY STATUS RESTARTS AGE scale-nginx-898f5b6d4-ftffd 1/1 Running 0 16s scale-nginx-898f5b6d4-ftffd 1/1 Terminating 0 70s scale-nginx-898f5b6d4-ftffd 0/1 Terminating 0 72s scale-nginx-898f5b6d4-ftffd 0/1 Terminating 0 72s scale-nginx-898f5b6d4-ftffd 0/1 Terminating 0 75s scale-nginx-898f5b6d4-ftffd 0/1 Terminating 0 75s
以上よりAzure Blob Storageのeventからpodをscaleできた。
運用を考えてみる
リソース監視からのauto scale
背景で述べているようにkubernetesの標準機能はmemoryやcpuをtriggerにするため、Databaseのような外部リソースやpod内のthread、connection数といった他のmetricをtriggerにするのが困難でした。KEDAを利用することでAzure Monitorなどといった監視サービスと併用することでpodのconnection数が上限をtriggerにscale outするなどの運用方法が考えられます。 ただし、scale outする場合の他のリソースへの影響を考慮するため キャパシティプランニングする必要はあります。
Serverlessの実行
Serverlessアプリケーションは、AWS LambdaやAzure FunctionsなどのFaaSやAzure Container Instance(ACI) によるpodの起動など、さまざまな方法が挙げられます。もちろん、これらの仕組みでも十分に実現できますが、KEDAを利用することでkubernetes cluster内に一元管理できるためコストが楽になると感じました。 とくに長時間のbatch処理は「Azure Queue Storage → KEDAによるAuto Scale」といったシンプルな実装で管理でき、タイムアウト意識する必要も減るため有用な仕組みになりそうです。
所感
触ってみた印象としてKEDAは、kubernetes cluster内で実現するFaaSのイメージです。とくにkubernetesを普段運用している方は、扱いやすいものだと思います。 プロダクトを安定させる使い方や、新機能を効率よく動かす使い方など、プロダクトの課題に沿った形で柔軟に使えそうなので、auto scale や batch処理なの運用設計に困っている人がいれば是非触ってみてほしいです。