はじめに
負荷試験って目的とは
負荷試験の指標
- スループット
- 単位時間に処理を行う量
- webシステムでは「1秒間に処理を行うHTTPリクエストの数」を示すことが多く、rps(Request Per Second)と呼ぶ
- 「ネットワーク上を流れるデータ転送速度」として利用する場合もある
- ネットワーク帯域と呼ぶ
- 単位時間に処理を行う量
- レイテンシ
システムの性能改善
- スループットの改善
- レイテンシの改善
マイクロサービスにより構築されたwebアプリケーションのテストコードではサービス間の通信が発生するケースがある。 これまではmockingjay-serverを利用して外部サービスのmockを作成しサービステストを実装していたが、エラー発生ケースのmock定義が非常に煩雑になると感じた。 且つ、マイクロサービス間で頻繁に呼ばれるAPIに関してはエラーケースを定義することで他のテストケースへの影響も発生した。 これらのことから、テストケース間で依存関係を与えない方法でサービステストが実装出来ないかを調査したところWireMockが候補に挙がったためシンプルではあるが実装例を残しておく。
本検証ではmavenを利用しているため、公式サイトの手順に沿って下記の依存性をpomに記入する。
後はmvn installで依存ライブラリをインストール出来る。
<dependency>
<groupId>com.github.tomakehurst</groupId>
<artifactId>wiremock</artifactId>
<version>2.17.0</version>
<scope>test</scope>
</dependency>
java.lang.NoClassDefFoundError: org/eclipse/jetty/util/thread/Locker
at org.eclipse.jetty.server.Server.<init>(Server.java:94)
at com.github.tomakehurst.wiremock.jetty9.JettyHttpServer.createServer(JettyHttpServer.java:118)
at com.github.tomakehurst.wiremock.jetty9.JettyHttpServer.<init>(JettyHttpServer.java:66)
at com.github.tomakehurst.wiremock.jetty9.JettyHttpServerFactory.buildHttpServer(JettyHttpServerFactory.java:31)
at com.github.tomakehurst.wiremock.WireMockServer.<init>(WireMockServer.java:74)
at com.github.tomakehurst.wiremock.junit.WireMockClassRule.<init>(WireMockClassRule.java:32)
at com.github.tomakehurst.wiremock.junit.WireMockClassRule.<init>(WireMockClassRule.java:40)
at spark.unit.service.ServiceTests.<clinit>(ServiceTests.java:26)
at sun.misc.Unsafe.ensureClassInitialized(Native Method)
at sun.reflect.UnsafeFieldAccessorFactory.newFieldAccessor(UnsafeFieldAccessorFactory.java:43)
at sun.reflect.ReflectionFactory.newFieldAccessor(ReflectionFactory.java:156)
at java.lang.reflect.Field.acquireFieldAccessor(Field.java:1088)
at java.lang.reflect.Field.getFieldAccessor(Field.java:1069)
at java.lang.reflect.Field.get(Field.java:393)
at org.junit.runners.model.FrameworkField.get(FrameworkField.java:73)
at org.junit.runners.model.TestClass.getAnnotatedFieldValues(TestClass.java:230)
at org.junit.runners.ParentRunner.classRules(ParentRunner.java:255)
at org.junit.runners.ParentRunner.withClassRules(ParentRunner.java:244)
at org.junit.runners.ParentRunner.classBlock(ParentRunner.java:194)
at org.junit.runners.ParentRunner.run(ParentRunner.java:362)
at org.junit.runner.JUnitCore.run(JUnitCore.java:137)
at com.intellij.junit4.JUnit4IdeaTestRunner.startRunnerWithArgs(JUnit4IdeaTestRunner.java:68)
at com.intellij.rt.execution.junit.IdeaTestRunner$Repeater.startRunnerWithArgs(IdeaTestRunner.java:51)
at com.intellij.rt.execution.junit.JUnitStarter.prepareStreamsAndStart(JUnitStarter.java:237)
at com.intellij.rt.execution.junit.JUnitStarter.main(JUnitStarter.java:70)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:147)
Caused by: java.lang.ClassNotFoundException: org.eclipse.jetty.util.thread.Locker
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:331)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 30 more
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-server</artifactId>
<version>9.3.14.v20161028</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-servlets</artifactId>
<version>9.3.14.v20161028</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-servlet</artifactId>
<version>9.3.14.v20161028</version>
<scope>test</scope>
</dependency>
wiremock-standaloneの依存ライブラリをpomに追加する <dependency>
<groupId>com.github.tomakehurst</groupId>
<artifactId>wiremock-standalone</artifactId>
<version>${wiremock.version}</version>
<scope>test</scope>
</dependency>
今回はマイクロサービスで構築されたアプリケーションを想定してサービステストコードを実装する。
外部サービスの呼出し結果により処理が変更される

上記処理の場合、Aサービスの「/user/insert」に対するサービステストを実装する場合、テスト結果がBサービスに依存することがわかる。
// wiremockをポートを指定して定義する @Rule public WireMockClassRule wireMockRule = new WireMockClassRule(8082); @Test public void TEST_Bサービス正常動作時() throws UnirestException { // Bサービスの正常動作をmockとする wireMockRule.stubFor(get(urlEqualTo("/mock/sample")) .willReturn( aResponse() .withStatus(200) .withHeader("Content-Type", "application/json") .withBody("OK"))); HttpResponse<String> res = Unirest.post("http://localhost:8081/user/insert") .header("Content-Type", "application/json") .asString(); assertEquals("response codeが200であること:", 200, res.getStatus()); assertEquals("response bodyがOKであること:", "OK", res.getBody()); } @Test public void TEST_Bサービス異常動作時() throws UnirestException { // Bサービスの異常動作をmockとする wireMockRule.stubFor(get(urlEqualTo("/mock/sample")) .willReturn( aResponse() .withStatus(400) .withHeader("Content-Type", "application/json") .withBody("B Service Error"))); HttpResponse<String> res = Unirest.post("http://localhost:8081/user/insert") .header("Content-Type", "application/json") .asString(); assertEquals("response codeが400であること:", 400, res.getStatus()); assertEquals("response bodyがB Service Errorであること:", "B Service Error", res.getBody()); }

当初の想定通りテストケース間で依存を与えずにサービステストの実装を行えた。かつ導入手順もシンプルである為非常に扱いやすい。 mock管理のフレームワークといえばswaggerが有名であるが、今回のようなテスト目的のみであればWireMockが導入コスト面から言ってもおすすめである。
※外部のmockサーバーに管理している場合は、mockを用いたテスト時にテストが失敗するため検知できる。 ※今回のように利用する場合は、サービス間の関連図を作成しておく必要があると思う。
マイクロサービスにより構築されたwebアプリケーションのテストコードではサービス間の通信が発生するケースがある。今回はサービス間の通信が発生するテストの実装を実装するためmockツールを検証したので導入手順を残しておく。
WireMock thoughtworksのTechnology Radarでも紹介されており、この1年間でも進化が著しいとのことなので、さっそく試してみる。
HTTPベースのAPIのシミュレータ、mockサーバー。 http://wiremock.org/ https://github.com/tomakehurst/wiremock
WireMockはjarファイルで提供されており、起動についてはこれを実行する。 http://repo1.maven.org/maven2/com/github/tomakehurst/wiremock-standalone/2.17.0/wiremock-standalone-2.17.0.jar
$java -jar wiremock-standalone-2.12.0.jar
http://localhost:8080でmockサーバーが起動する

※Chrome Postmanを使用して検証を実施
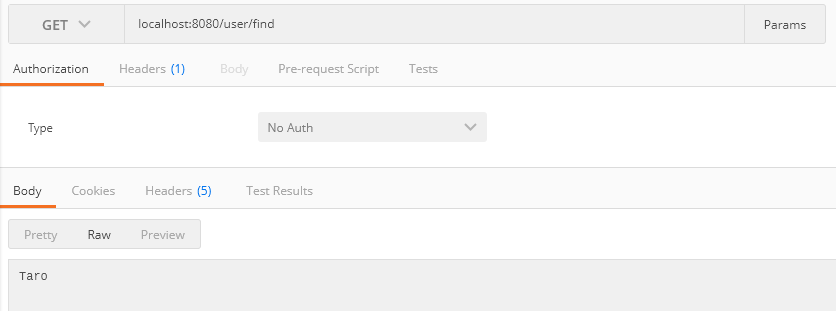
特定のリクエストに対して指定したレスポンスを返す設定を行う。
なお、マッピングにはWireMockの/__admin/mappingsAPIを使用する。
POST : /__admin/mappings
- /helloのPOST APIを定義する

登録された結果が返却される

設定した結果が返却される。

登録されたAPIはwiremock-standalone-2.12.0.jarと同一階層のmappingsに保存される。



{
"scenarioName": "findUser",
"request": {
"url": "/user/find",
"method": "GET"
},
"response": {
"status": 200,
"body": "Taro",
"headers": {
"Content-Type": "application/json"
}
}
}
__admin/docsを開きSwagger UIの管理画面で確認できる。

GitOpsというキーワードが出てきており、職場でもGitOpsを使った検証環境の運用が始まっている。
しかし、GitOps環境を構築するにあたってIaCは進めているものの、まだ人手によるOperationがなくなっていないのも事実です。
そこで、Azure上にkubernetes clusterの構築からGitOpsの仕組みを導入するまでを自動化する仕組みとして
Bedrockを検証したので手順や気づきについてまとめていきます。
Weaveworks社が提唱した,Kubernetesの運用ベストプラクティス
詳しくはGitOpsを参照
記事はボリュームがあるので 要点をまとめると下記のような感じです。
GitOpsを実現するために、 現在はFluxというOSSを使ってkubernetes clusterの状態とgit管理しているmanifestの間で 同期を取る仕組みを実現している。
fluxについて過去にチュートリアル記事を書いたので参考になればと思います。 cabi99.hatenablog.com
現在はFluxを使って下図の環境を構築しています。
この環境をpipeline以外、すべて自動で構築します。

Microsoftが提供するGitOpsワークフローを使用してKubernetesクラスターを運用可能にするterraformテンプレートです。 GitOpsワークフローは、Fabrikateの定義を中心に展開されており、構成から構成を分離する、より高い抽象化レベルで展開を指定できます。 今回の検証ではBedrockを使ってAKSクラスターを自動構築することを優先したのでFabrikateについては検証しません。
helm: v2.13.1 → 3系だとまだ動かないっぽい
terraform: v0.12.20 → テンプレートは古いバージョン対応だったのでupgradeコマンドでスクリプトを更新しました
Azure CLI
$ az version
{
"azure-cli": "2.0.80",
"azure-cli-command-modules-nspkg": "2.0.3",
"azure-cli-core": "2.0.80",
"azure-cli-nspkg": "3.0.4",
"azure-cli-telemetry": "1.0.4",
"extensions": {}
}
bedrockのテンプレートで実行している内容を簡単に書くと以下になります。
1.azure cli でresource groupを作成する
az group create -n gitOpsCluster -l japaneast

2.vnetとsubnetをterraformで作成する ※利用するfileはbedrockの以下path
/bedrock/cluster/azure/vnet
参考までにmain.tf variables.tfはresource_group_name以外、ほぼデフォルト値
resource "azurerm_virtual_network" "vnet" {
name = var.vnet_name
location = var.location
address_space = [var.address_space]
resource_group_name = var.resource_group_name
dns_servers = var.dns_servers
tags = var.tags
}
resource "azurerm_subnet" "subnet" {
count = length(var.subnet_names)
name = var.subnet_names[count.index]
virtual_network_name = azurerm_virtual_network.vnet.name
resource_group_name = azurerm_virtual_network.vnet.resource_group_name
address_prefix = var.subnet_prefixes[count.index]
service_endpoints = var.subnet_service_endpoints[count.index]
}

3.aksクラスターを作成し、fluxをinstallする ※利用するfileはbedrockの以下path
/bedrock/cluster/azure/aks-gitops
参考までにmain.tf variables.tfはfluxの設定値やkey情報以外はほぼデフォルト値
module "aks" {
source = "../../azure/aks"
resource_group_name = var.resource_group_name
cluster_name = var.cluster_name
agent_vm_count = var.agent_vm_count
agent_vm_size = var.agent_vm_size
dns_prefix = var.dns_prefix
vnet_subnet_id = "/subscriptions/${var.azure_subscription_id}/resourceGroups/${var.resource_group_name}/providers/Microsoft.Network/virtualNetworks/${var.virtual_network_name}/subnets/${var.agent_subnet_name}"
ssh_public_key = var.ssh_public_key
service_principal_id = var.service_principal_id
service_principal_secret = var.service_principal_secret
service_cidr = var.service_cidr
dns_ip = var.dns_ip
docker_cidr = var.docker_cidr
kubeconfig_filename = var.kubeconfig_filename
network_policy = var.network_policy
network_plugin = var.network_plugin
oms_agent_enabled = var.oms_agent_enabled
}
module "flux" {
source = "../../common/flux"
gitops_ssh_url = var.gitops_ssh_url #Azure DevOpsのgitで管理しているリポジトリ
gitops_ssh_key = var.gitops_ssh_key #fluxがAzure DevOpsにアクセスするためのkey
gitops_path = var.gitops_path #fluxが同期したいマニフェストのpath
gitops_poll_interval = var.gitops_poll_interval
gitops_label = var.gitops_label
gitops_url_branch = var.gitops_url_branch #fluxが同期したいbranch
enable_flux = var.enable_flux
flux_recreate = var.flux_recreate
kubeconfig_complete = module.aks.kubeconfig_done
kubeconfig_filename = var.kubeconfig_filename
flux_clone_dir = "${var.cluster_name}-flux"
acr_enabled = var.acr_enabled
gc_enabled = var.gc_enabled
}
module "kubediff" {
source = "../../common/kubediff"
kubeconfig_complete = module.aks.kubeconfig_done
gitops_ssh_url = var.gitops_ssh_url
}
Azure DevOpsでssh_keyを発行する手順はこちらを参照
Connect to your Git repos with SSH - Azure Repos | Microsoft Docs
fluxで同期を行うmanifestをkustomizeを使って管理している場合はfluxのoptionに注意する必要があります。 bedrockでfluxをインストールするのはhelmを利用しているのですが、「manifestGeneration」optionが変数として受け渡す設計がなされていないので自分たちで修正する必要があります。
/cluster/common/flux/deploy_flux.sh
#!/bin/sh while getopts :b:f:g:k:d:e:c:l:s:r:t:z: option do case "${option}" in b) GITOPS_URL_BRANCH=${OPTARG};; f) FLUX_REPO_URL=${OPTARG};; g) GITOPS_SSH_URL=${OPTARG};; k) GITOPS_SSH_KEY=${OPTARG};; d) REPO_ROOT_DIR=${OPTARG};; e) GITOPS_PATH=${OPTARG};; c) GITOPS_POLL_INTERVAL=${OPTARG};; l) GITOPS_LABEL=${OPTARG};; s) ACR_ENABLED=${OPTARG};; r) FLUX_IMAGE_REPOSITORY=${OPTARG};; t) FLUX_IMAGE_TAG=${OPTARG};; z) GC_ENABLED=${OPTARG};; *) echo "Please refer to usage guide on GitHub" >&2 exit 1 ;; esac done KUBE_SECRET_NAME="flux-ssh" RELEASE_NAME="flux" KUBE_NAMESPACE="flux" CLONE_DIR="flux" REPO_DIR="$REPO_ROOT_DIR/$CLONE_DIR" FLUX_CHART_DIR="chart/flux" FLUX_MANIFESTS="manifests" echo "flux repo root directory: $REPO_ROOT_DIR" rm -rf "$REPO_ROOT_DIR" echo "creating $REPO_ROOT_DIR directory" if ! mkdir "$REPO_ROOT_DIR"; then echo "ERROR: failed to create directory $REPO_ROOT_DIR" exit 1 fi cd "$REPO_ROOT_DIR" || exit 1 echo "cloning $FLUX_REPO_URL" if ! git clone -b "$FLUX_IMAGE_TAG" "$FLUX_REPO_URL"; then echo "ERROR: failed to clone $FLUX_REPO_URL" exit 1 fi cd "$CLONE_DIR/$FLUX_CHART_DIR" || exit 1 echo "creating $FLUX_MANIFESTS directory" if ! mkdir "$FLUX_MANIFESTS"; then echo "ERROR: failed to create directory $FLUX_MANIFESTS" exit 1 fi # call helm template with # release name: flux # git url: where flux monitors for manifests # git ssh secret: kubernetes secret object for flux to read/write access to manifests repo echo "generating flux manifests with helm template" # ここにmanifestGenerationがないため、kustomizeでmanifestをgenerateする場合はoptionを追加する必要があります。 # こんな感じ「--set manifestGeneration=true」 if ! helm template . --name "$RELEASE_NAME" --namespace "$KUBE_NAMESPACE" --values values.yaml --set image.repository="$FLUX_IMAGE_REPOSITORY" --set image.tag="$FLUX_IMAGE_TAG" --output-dir "./$FLUX_MANIFESTS" --set git.url="$GITOPS_SSH_URL" --set git.branch="$GITOPS_URL_BRANCH" --set git.secretName="$KUBE_SECRET_NAME" --set git.path="$GITOPS_PATH" --set git.pollInterval="$GITOPS_POLL_INTERVAL" --set git.label="$GITOPS_LABEL" --set registry.acr.enabled="$ACR_ENABLED" --set syncGarbageCollection.enabled="$GC_ENABLED"; then echo "ERROR: failed to helm template" exit 1 fi # back to the root dir cd ../../../../ || exit 1 echo "creating kubernetes namespace $KUBE_NAMESPACE if needed" if ! kubectl describe namespace $KUBE_NAMESPACE > /dev/null 2>&1; then if ! kubectl create namespace $KUBE_NAMESPACE; then echo "ERROR: failed to create kubernetes namespace $KUBE_NAMESPACE" exit 1 fi fi echo "creating kubernetes secret $KUBE_SECRET_NAME from key file path $GITOPS_SSH_KEY" if kubectl get secret $KUBE_SECRET_NAME -n $KUBE_NAMESPACE > /dev/null 2>&1; then # kubectl doesn't provide a native way to patch a secret using --from-file. # The update path requires loading the secret, base64 encoding it, and then # making a call to the 'kubectl patch secret' command. if [ ! -f "$GITOPS_SSH_KEY" ]; then echo "ERROR: unable to load GITOPS_SSH_KEY: $GITOPS_SSH_KEY" exit 1 fi secret=$(< "$GITOPS_SSH_KEY" base64 -w 0) if ! kubectl patch secret $KUBE_SECRET_NAME -n $KUBE_NAMESPACE -p="{\"data\":{\"identity\": \"$secret\"}}"; then echo "ERROR: failed to patch existing flux secret: $KUBE_SECRET_NAME " exit 1 fi else if ! kubectl create secret generic $KUBE_SECRET_NAME --from-file=identity="$GITOPS_SSH_KEY" -n $KUBE_NAMESPACE; then echo "ERROR: failed to create secret: $KUBE_SECRET_NAME" exit 1 fi fi echo "Applying flux deployment" if ! kubectl apply -f "$REPO_DIR/$FLUX_CHART_DIR/$FLUX_MANIFESTS/flux/templates" -n $KUBE_NAMESPACE; then echo "ERROR: failed to apply flux deployment" exit 1 fi
aksのデプロイが完了するとfluxの同期によりapplicationがデプロイされます。
今回はaksチュートリアルにあるvoteアプリを使いました。
クイック スタート:Azure Kubernetes Service クラスターをデプロイする | Microsoft Docs
デプロイされたらexternal-ipを取得してアクセス出来ます。
$ kubectl get svc -o wide NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR azure-vote-back ClusterIP 10.0.111.235 <none> 6379/TCP 10m app=azure-vote-back azure-vote-front LoadBalancer 10.0.55.117 23.102.68.224 80:31559/TCP 10m app=azure-vote-front kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 22m <none>
アクセスすると無事表示されました。

デフォルトですと「default」namespaceにfluxのpodがdeployされるので別で管理したい場合はoptionを変更したほうが良いかもしれません。
$ kubectl get po --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE default azure-vote-back-bc5b86f5f-dpskl 1/1 Running 0 14m default azure-vote-front-ccfd8667f-rt8rc 1/1 Running 0 14m flux flux-6455b87976-7thxx 1/1 Running 0 15m flux flux-memcached-5ff94b674c-t9qcm 1/1 Running 0 15m kube-system azure-cni-networkmonitor-bjxvq 1/1 Running 0 22m kube-system azure-ip-masq-agent-pltrz 1/1 Running 0 22m kube-system azure-npm-79bxx 2/2 Running 0 17m kube-system coredns-544d979687-dzrxw 1/1 Running 0 26m kube-system coredns-autoscaler-546d886ffc-s8ssf 1/1 Running 0 26m kube-system dashboard-metrics-scraper-867cf6588-9llkt 1/1 Running 0 26m kube-system kube-proxy-nvxvm 1/1 Running 0 22m kube-system kubernetes-dashboard-7f7676f7b5-dnrcc 1/1 Running 0 26m kube-system metrics-server-75b8b88d6b-spllf 1/1 Running 1 26m kube-system tunnelfront-6dcfb8d9d9-vrtvr 1/1 Running 0 26m
検証していて気になったこととして、FluxのDocker imageのリポジトリです。 もともとfluxはFlux projectの「fluxcd」リポジトリからpullしていると想定していましたが 実際はweaveworksのリポジトリからでした。
両リポジトリを比較するとfluxcdの方がversionは新しいようです。
weaveworks weaveworks/flux:1.14.2 fluxcd fluxcd/flux:1.17.1
この違いに関しては
weaveworksの「Flagger」というプロダクトがFluxを利用したcanary デプロイを実現する仕組みがあり対応しているFluxをweaveworks自身が管理しているのではないかと推測しています。
今回はbedrockを使ってAzure上にGitOps対応のAKSクラスターを手動で作成しました。
これらの工程はAzure DevOpsのpipelinesのようなCIツールで自動化することが可能なので自動化できればエンジニアは 特に意識せずにテスト環境を構築できるようになります。
fluxを使ってclusterのgitOpsは実現できていますが、terraformのコードと環境が同期を取っているわけではないので、 実際に環境に関してもgitOpsを行いたい場合はFabrikateを導入してCI pipelineを構築することが必要になります。
検証してみた感想としてあまり抽象化しすぎると、管理や保守の面で結果的に属人化してしまう恐れもあるので テスト環境のような使い捨ての環境を作る場合は、今回のようなterraformスクリプトを自動化するpipelineのみでも十分だと感じました。
「クラウドネイティブ」という言葉をよく聞くのですが、正直「クラウドネイティブってなんだよ?」という疑問があったり「エンジニアとしてどうするの?」など個人としては不透明な部分が多くモヤモヤしていました。
そこで先日、「Cloud Native Talk Night vol.2」に参加してきて貴重なお話が聞けたので整理がてらまとめていこうと思います。
「クラウドネイティブ」というキーワードはエンタープライズの世界に広く浸透している中、そんな世界の最先端では何が起きていて、 どんな人が何を考えているのかについて、OSS界隈に精通したエンジニアをゲストに招きお話を聞く会でした。
参加パネリスト
株式会社レクター 広木 大地 氏
IBM Champion 羽山 祥樹 氏
セッションでは狭義のクラウドネイティブについて簡単な説明がありました。
詳細についてはCNCF(Cloud Native Computing Foundation) が定義しているので、
そちらを参考にして頂ければと思います。
クラウドネイティブ技術は、パブリッククラウド、プライベートクラウド、ハイブリッドクラウドなどの近代的でダイナミックな環境において、スケーラブルなアプリケーションを構築および実行するための能力を組織にもたらします。 このアプローチの代表例に、コンテナ、サービスメッシュ、マイクロサービス、イミュータブルインフラストラクチャ、および宣言型APIがあります。
これらの手法により、回復性、管理力、および可観測性のある疎結合システムが実現します。 これらを堅牢な自動化と組み合わせることで、エンジニアはインパクトのある変更を最小限の労力で頻繁かつ予測どおりに行うことができます。
Cloud Native Computing Foundationは、オープンソースでベンダー中立プロジェクトのエコシステムを育成・維持して、このパラダイムの採用を促進したいと考えてます。 私たちは最先端のパターンを民主化し、これらのイノベーションを誰もが利用できるようにします。
自分なりに要約すると、クラウド利用にあたっていくつかの代表的なアプローチがあり、それらを用いるとシステムに対する変更を安全かつ迅速に行うことが出来るようになりました。
CNCFではこれらの仕組みを民主化して誰もが利用できるようにしています。
クラウドを利用するにあたって、何から始めた方が良いのか? それはどのようなメリット/デメリットがあるのか?などに対して具体的な名称を述べているので エンジニアにはとっかかりやすい定義になっていると思います。
このセッションでは、パネリストの方々が「広義のクラウドネイティブ」について、
どのように考えているかの話がありました。
皆さん、共通してエンジニアリングが事業やユーザーの価値に近づくという表現をされており 中でも私は広木 大地さんの「溶けること」というフレーズが印象に残っています。 これまで自分が認識していたクラウドネイティブはエンジニアのものであり、 ビジネス層などにはあまり関係のないものだと思っていました。
ですが、今回のセッションの中で事業やユーザーの価値に近づくにはスピードを出す必要があり そのためには、組織にクラウドネイティブ的な考えが浸透し、エンジニアに限らず誰もが利用できる環境を重要なのだと感じました。
そして、その考え方はリーンをはじめとする既に私たちが知っている概念やプラクティスであり クラウドが主流になる前からエンジニアをやっている立場としての気づきは「アジャイルな思想にエンジニアリングが追いついた」という印象です。
今回の「Cloud Native Talk Night」する前と後で自分が学んだこととしては、
当たり前が常に変化していっているということです。これまで自分の当たり前はクラウドや技術のことは、エンジニアの守備範囲だと考えていましたが、 それではスピード感も出ませんし、組織が変化にも耐えられません。 その問題を解決するためにも、組織として距離を縮めていく必要があるのだと感じました。
現在はSREとしてシステムの信頼性をあげることをミッションとして進めていますが それだけでなく、組織間のサイロを取り壊すことと、組織全体にエンジニアリングの必要性を 広める役割をやりたいと思いました。
Agile Talks vol.1に参加してきました。 楽しい話がたくさん聞けたので自分の頭の中を整理するためにも メモを記録に残そうと思います。 agiletalks.connpass.com
@teyamaguさんが企画しているです。 ただただ@teyamaguさんが聞きたい講演や参加したいワークショップを聞く/参加する会で XP祭りでもRSGTでも経験できない…かもしれない貴重かつほっこりする会だと認識してます。
今回のコンテンツは大規模アジャイルとレトロスペクティブのお話でした。
1.「アジャイルコーチから見たScaled Agile Method.. ~SAFe and LeSSから学ぶ勘所~」
www.slideshare.netMasataka Mizunoさんが司会を務めてくださり SAFe派のIwao HaradaさんとLeSS派のTakao Kimuraさんが原理・原則を紹介しつつ 互いの相違点や類似点を話していく会でした。
メモ・感想
メモ・感想
大規模スクラムについて話を聞くのが初めてだったので、初めましてな言葉がたくさんでした。 ひとまず、SAFeにせよLeSSにせよ大規模になってくると、リーダーや上級マネジメント層が重要な役割を担っている。 よくスクラムでは自己組織化されたチームという表現があるが、大規模アジャイルの場合は、横連携であったり強力な推進力がないと 難しいのだろうなと感じました。チームの自己組織化はチームメンバーの問題であり、横連携とかサイロになりがちな部分は全体像を見渡す リーダーとかが重要なのだと認識しました。 まだまだ、大規模アジャイルについて学習していないので、これを機にちゃんと学習してみようと思います。
 アジャイルとスクラムを大規模に実装する方法")
大規模スクラム Large-Scale Scrum(LeSS) アジャイルとスクラムを大規模に実装する方法
2. 「レトロ・オブ・ザ・デッド ~ゾンビレトロしてたチームを2年間観察していたら、良い振り返りをするようになったので、その活動報告~」 github.com
アジャイルコーチとして2年間同じチームを見続けているRyo Tanakaさんのお話。 自己紹介の写真は有料の写真なので貴重らしいです。 チームを観察して気づいたことやレトロスペクティブについての考えが聞けた会でした。
メモ・感想
レトロは普段から自分たちもやっていることなので共感できる部分や参考になることが多かったです。 特に「自己肯定的チーム」は大事にしている考えだったのですが、言語化されていて、 これからたくさん使っていきたいフレーズでした。 他の学びとしては、「帆船ふりかえり」は面白そうなので自分のチームでも取り組んでみようと思います。
Ryo Tanakaさんのお話の中で「チームは問題解決を見てはいけない」という言葉があり どういうことなのか考えてみてくださいという話があったので、自分なりに考えてみました。
このフレーズを見たときに直感的に思い浮かんだことは、目先の問題であったり長期的な問題にとらわれるのではなく あくまで、チームは「ゴール」を見据えて進むことが重要という意味ではないのかと認識しました。
なぜならば、目先の問題は人や役割によって見えるものが異なるので、チームが問題解決に注力してしまうと 方向性がぶれる危険があるからだと考えています。 その点、「ゴール」に関しては人や役割が異なっていようが、同じものを目指しているはずなので「ゴール」を見据えて 行動することで、常にベクトルの方向が揃うから、気が付いたら何やっているだっけ?状態にならずに済むような気がしました。
このような状態を作るためによくインセプションデッキなどの手法が使われると思いますが チームでも同じようにインセプションデッキを作って、常に向きなおれる準備をすることが大切なのかな?
なんかうまくまとまっていない気もしますが、個人的にはこんな意見です。 他に意見があればぜひ共有いただきたいです。
大人数でインセプションデッキを決める機会があったので自分たちがやったこと、わかったことをまとめておく。 今後、大人数でやる機会があるときに参考になればと思う。
ここではインセプションデッキの詳細については特に説明しない。 インセプションデッキ自体は他に分かりやすい資料があるのでここに共有しておく。
www.slideshare.netインセプションデッキとは、プロジェクトの全体像(目的、背景、優先順位、方向性等)を端的に伝えるためのドキュメントである。 ThoughtWorks社のRobin Gibson氏によって考案され、その後、アジャイルサムライの著者 Jonathan Rasmusson氏 によって広く認知されるようになっている。
インセプションデッキのひな形があるのでリンクを紹介しておく。 github.com
テンプレートのインセプションデッキは主に以下のような構成になっている。
もともとプロジェクトに定義のようなものは存在したが 一部のメンバーのみで決めたのでチームのメンバに見てもらえなかったり、読んでも理解が困難だった。 そこで、私たちのアジャイルプロジェクトにおいては、インセプションデッキを用いてプロジェクトに対する期待をマネジメントするため。
人数が多いので、どのような進め方をするかなど事前に設計した。 ここでは、進め方や実際に自分たちが使ったインセプションデッキについて 簡単に紹介する。
インセプションデッキのテンプレートを自分たちのプロジェクトに適応しずらい部分が 多かったり、既にまとめられている項目があったりと情報量が多かったため あらかじめテーマをいくつか絞ったカスタマイズ版を使った。 カスタマイズした中には、テンプレートと同じ意味合いでも表現を変えたり 順番を変えることでメンバーがイメージしやすいことを意識している。
ファシリテーター:2名
参加者:約20名
インセプションデッキを作るにあたって 私たちの設計したやり方はこんな感じだ。
集められたメンバーの中には、インセプションデッキが何なのか不明なメンバーもいるので 全員のインセプションデッキについてのイメージを統一するためにも説明をした。
なぜインセプションデッキが必要になっているかを説明する。 インセプションデッキを作成する理由を明確にすることで解決したい内容が何なのか?を明確にすることで 参加メンバーの目的意識が明確になる。
参加人数が多いと意見を出す人が偏ってしまったり、十分な対話が出来ないことが多いので 今回はグループワークを採用した。 大体4~5名くらいのグループを作り各自意見を出しやすい場を作る。
私たちのチームが普段ふりかえりのファシリテーションの時にやるDPAというアクティビティを取り入れた。 どのような雰囲気でインセプションデッキ決めの会を進めたいか? 決めた雰囲気を実現するために具体的に何を行ったら良いか?をグループで考えてもらい みんなのインセプションデッキ決めのルールとした。 目的として自分たちでルールを決めることで、この会が他人事ではなく自分事になるようにする狙いがある。
ちなみにみんなが決めたルールとアクションは以下になる
※ルールやアクションが多いと守るのが大変なので2~3個くらいに抑えるのがおすすめ
インセプションデッキの各テーマをグループワークして考えてもらった。 1テーマごとに共有してスライドを埋めていくスタイル。
グループワークの内訳
個人でテーマについて考える - 5 min
グループ内で共有/まとめ - 15 min
グループ間で共有/まとめ - 10 ~ 15 min
やってみると分かるが、少数に分けると普段発言しない人も 発言するようになるので貴重な意見が聞けることが多かったりする。 特に、普段別の役割として仕事している人同士の方が多角的な意見が出やすいので グループ分け時に少し工夫してみると良いかもしれない。
また、テーマについてグループワークでディスカッションすることも効果的である。 私たちの場合は、インセプションデッキのトレードオフスライダーの各項目を定義をグループワークで決めた。 これにより、各項目が何を意味しているのか全員が明確になるため、後になって認識の違いが生まれることが少ない。
インセプションデッキの全てのテーマについて決まったら全体を通して確認してみる。 全体像が見えてくると「やらないこと」が変わったり微調整する部分があるので 自分たちのデッキを確認しなおすことをおすすめしたい。
インセプションデッキの中で発生したリスクや別途考える系の問題を具体的なアクションに落とし込む。 本来であれば、インセプションデッキ会の中で解決したいものもあるが時間の制約や人の集まりにくさがある場合がある。 私たちの場合は、問題やリスクに対して「なぜ、なにを」の部分が明確だったので 「誰が、いつ、どこで、どうやって」だけは明確にして別途決める会のスケジュール等を明確にして リスクなどがそのままにならないように注意した。
インセプションデッキを決めると関係者全員が同じ方向を向くことが出来るし 道に迷ったときに見直すと軌道修正出来るので、プロジェクトに限らずチームでもインセプションデッキを作ったほうが良いと思う。 今回はファシリテーターの立場として参加したが、みんなが対話してどんどん決まっていくのは、見ていて凄く楽しかったので今後も社内でやっていきたいと思う。
インセプションデッキが紹介されている書籍